本文共 10385 字,大约阅读时间需要 34 分钟。
Tensorflow并非一套特定机器学习库——相反,其属于一套通用型计算库,负责利用图形表达计算过程。其核心通过C++语言实现,同时亦绑定有多种其它语言。与Python绑定不同的是,Go编程语言绑定不仅允许用户在Go环境当中使用TensorFlow,同时亦可帮助大家深入了解TensorFlow的内部运作原理。
\\什么是绑定?
\\从官方说明的角度来看,TensorFlow的开发者们公布了:
\\- C++源代码:TensorFlow的真正核心,负责具体实现这套机器学习库的各高/低层级操作。\\t
- Python绑定与Python库:这些绑定由C++实现代码所自动生成,这意味着我们能够借此利用Python调用C++函数:举例来说,我们可以借此实现numpy。另外,这套库还将调用与绑定相结合,旨在定义TensorFlow用户们所熟知的各类高层级API。\\t
- Java绑定。\\t
- Go绑定。\
作为Go的忠诚支持者,我当然对Go绑定给予了高度关注,希望了解其适用于支持哪些任务类型。
\\Go绑定说明
\\
Gopher (由Takuya Ueda(@tenntenn)创建,基于Creative Commons 3.0 Attribution许可)
\\与TensorFlow Logo结合在一起。
\\首先需要强调的是用于进行自身维护的Go API缺少Variable支持能力:此API的设计目标在于使用经过训练的模型,而非从零开始执行模型训练。这一点在说明文档中的“Go语言环境下TensorFlow安装”部分作出了明确提示:
\\\\\TensorFlow提供多种可在Go编程中使用之API。这些API的主要作用在于加载由Python语言创建的模型,并在Go应用程序之内执行这些模型。
\
如果我们不关注机器学习模型的训练,那么这些API不会引发任何麻烦。但如果大家需要进行模型训练,那么请注意以下建议:
\\\\\\\\\\\作为一位真正的Go语言支持者,请以简单作为基本指导原则!使用Python以定义并训练模型; 您始终可以加载经过训练的模型并随后在Go环境中加以使用。
\
简而言之:Go绑定可用于导入并定义常量图; 在这里的语境下,所谓常量是指不涉及任何训练过程,因此不存在经过训练的变量。
\\\\现在我们将利用Go语言深入探索TensorFlow世界:创建我们的第一款应用程序。
\\\\在接下来的内容中,我们假定大家已经拥有一套Go环境,并根据中的讲解对TensorFlow绑定进行了编译与安装。
\\了解TensorFlow结构
\\让我们再次对TensorFlow的概念进行重申(当然,这里是我个人总结出的概念,与中的描述有所不同):
\\\\\\\TensorFlow™为一套开源软件库,负责利用数据流图进行数值计算。图形中的各个节点代表数学运算,而图形边缘则代表着各节点之间进行通信的多维数据阵列(即张量)。
\
我们可以将TensorFlow视为一种描述性语言,其与SQL有点类似,大家可以在其中描述您所需要的内容,并由底层引擎(即数据库)解析您的查询、检查语法与语义错误,将其转换为专有表达、优化并得出计算结果:通过这一系列流程,我们将最终得出正确结果。
\\因此,在我们使用任何可用的API时,我们实际上是在对一个图形进行描述:此图形的评估起点始于我们将其放置于Session当中并明确决定在该会话内Run此图形。
\\了解到这一点,接下来让我们尝试定义一个计算图,并在一个Session当中对其进行评估。根据API说明文档的内容,我们可以明确找到tensorflow(简称为tf)\u0026amp; op软件包之内的可用方法列表。
\\如大家所见,这两个软件包当中包含一切对图形进行定义与评估所必需的要素。
\\前者包含构建基础性“空”结构——例如Graph本身——所需要的函数,而后者则包含各类最为重要的包,荐为由C++实现代码所自动生成的绑定。
\\然而,假定我们需要计划A与x之间的矩阵乘法,其中:
\\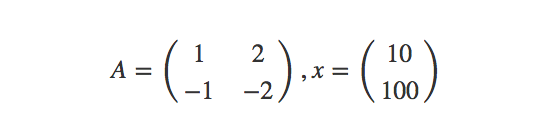
这里,假定大家已经熟悉了张量图的定义方式,并清楚了解占位符的概念及其实际作用。以下代码为TensorFlow Python绑定用户所作出的初步尝试。我们在这里将此文件命名为attempt1.go
\\\package main\import (\ \"fmt\"\ tf \"github.com/tensorflow/tensorflow/tensorflow/go\"\ \"github.com/tensorflow/tensorflow/tensorflow/go/op\")\func main() {\ // Let's describe what we want: create the graph\\ // We want to define two placeholder to fill at runtime\ // the first placeholder A will be a [2, 2] tensor of integers\ // the second placeholder x will be a [2, 1] tensor of intergers\\ // Then we want to compute Y = Ax\\ // Create the first node of the graph: an empty node, the root of our graph\ root := op.NewScope()\\ // Define the 2 placeholders\ A := op.Placeholder(root, tf.Int64, op.PlaceholderShape(tf.MakeShape(2, 2)))\ x := op.Placeholder(root, tf.Int64, op.PlaceholderShape(tf.MakeShape(2, 1)))\\ // Define the operation node that accepts A \u0026amp; x as inputs\ product := op.MatMul(root, A, x)\\ // Every time we passed a `Scope` to an operation, we placed that\ // operation **under** that scope.\ // As you can see, we have an empty scope (created with NewScope): the empty scope\ // is the root of our graph and thus we denote it with \"/\".\\ // Now we ask tensorflow to build the graph from our definition.\ // The concrete graph is created from the \"abstract\" graph we defined\ // using the combination of scope and op.\\ graph, err := root.Finalize()\ if err != nil {\ // It's useless trying to handle this error in any way:\ // if we defined the graph wrongly we have to manually fix the definition.\\ // It's like a SQL query: if the query is not syntactically valid\ // we have to rewrite it\ panic(err.Error())\ }\\ // If here: our graph is syntatically valid.\ // We can now place it within a Session and execute it.\\ var sess *tf.Session\ sess, err = tf.NewSession(graph, \u0026amp;tf.SessionOptions{})\ if err != nil {\ panic(err.Error())\ }\\ // In order to use placeholders, we have to create the Tensors\ // containing the values to feed into the network\ var matrix, column *tf.Tensor\\ // A = [ [1, 2], [-1, -2] ]\ if matrix, err = tf.NewTensor([2][2]int64{ {1, 2}, {-1, -2} }); err != nil {\ panic(err.Error())\ }\ // x = [ [10], [100] ]\ if column, err = tf.NewTensor([2][1]int64{ {10}, {100} }); err != nil {\ panic(err.Error())\ }\\ var results []*tf.Tensor\ if results, err = sess.Run(map[tf.Output]*tf.Tensor{\ A: matrix,\ x: column,\ }, []tf.Output{product}, nil); err != nil {\ panic(err.Error())\ }\ for _, result := range results {\ fmt.Println(result.Value().([][]int64))\ }}\\ 我们为以上代码编写了详尽的注释,希望大家认真关注以提升理解效果。
\\现在,TensorFlow-Python用户认为上述代码能够顺利完成编译并确切起效。让我们看看其判断是否正确:
\\\go run attempt1.go\\
下面来看得出的结果:
\\\panic: failed to add operation \"Placeholder\": Duplicate node name in graph: 'Placeholder'\\
很明显,这里出现了问题。可以看到,同一“Placeholder”名称之下存在两个计算“Placeholder”。
\\结论一:节点ID
\\每当我们调用一项方法以定义一项运算时,Python API都会生成不同节点——无论此前该方法是否曾经接受过调用。事实上,以下代码能够返回结果3,且不会引发任何问题。
\\\import tensorflow as tf\a = tf.placeholder(tf.int32, shape=())\b = tf.placeholder(tf.int32, shape=())\add = tf.add(a,b)\sess = tf.InteractiveSession()\print(sess.run(add, feed_dict={a: 1,b: 2}))\\ 我们可以验证此程序是否正确创建两个节点并输出其占位符名称: print(a.name, b.name)生成Placeholder:0 Placeholder_1:0。因此, b 占位符为Placeholder_1:0 而a 占位符为Placeholder:0。
\\不过在Go语言中,上述程序会发生错误,这是因为A与x皆会被称为Placeholder。我们可以得出以下结论:
\\Go API不会在我们每次调用一项用于定义运算的函数时自动生成新的名称:因此,运算名称是固定的,意味着我们无法加以修改。
\\提问时间:
\\- 到现在,我们了解到关于TensorFlow架构的哪些结论? 一套图形中的每个节点皆必须拥有一个惟一名称。每个节点皆由其名称作为标识。\\t
- 节点的名称与用于定义该节点的运算名称是否相同? 是的,或者更具体地讲,节点名称属于运算名称中的最后一部分。\
为了进一步澄清第二个问题,下面我们尝试解决节点名称重复问题。
\\结论二:范围
\\如大家所见,Python API会在每次定义一项运算时自动创建一个新的名称。着眼于底层,Python API会调用Scope类中的C++方法WithOpName。以下为scope.h当中列出的方法说明及其特征:
\\\/// Return a new scope. All ops created within the returned scope will have\/// names of the form \u0026lt;name\u0026gt;/\u0026lt;op_name\u0026gt;[_\u0026lt;suffix].\Scope WithOpName(const string\u0026amp; op_name) const;\\
大家可能已经注意到,此方法用于对节点进行命名以返回Scope,这意味着节点名称实际上就是一个Scope。所谓Scope,即为一条由root /(空图形)到op_name的完整路径。
\\当我们尝试添加一个拥有同样从/到op_name路径的节点时,WithOpName方法会相应添加一条_\u0026lt;suffix\u0026gt;后缀(其中\u0026lt;suffix\u0026gt;的为一个计数器),这意味着同一范围之内可存在重复节点。
\\了解了这一点,为解决节点名称重复的问题,我们显然需要在type Scope当中找到WithOpName方法。遗憾的是,此方法并不存在。
\\相反,通过查询type Scope相关说明文档,我们发现惟一能够返回新Scope的方法只有SubScope(namespace string)。
\\下面来看文档中的说明内容:
\\\\\\\SubScope会返回一个新的Scope,此Scope负责确保全部被添加至图形中的运算被命名为“namespace”。如果此命名空间与范围内的现有命名空间相冲突,则为其添加一个后缀。
\
使用后缀的冲突管理机制与C++ WithOpName方法有所区别:WithOpName会在同一范围内的运算名称之后添加suffix(因此Placeholder会变为Placeholder_1); 而Go的SubScope会将suffix添加至范围名称之后。
\\这种差异意味着最终生成的图形也将完全不同,然而这种图形层面的区别(即将节点放置在不同范围之下)并不会对计算结果造成任何改变——二者在计算上仍然等效。
\\下面我们变更该占位符定义以定义两个不同的节点,而后Print其Scope名称。
\\我们通过变更以下代码行创建文件attempt2.go:
\\\A := op.Placeholder(root, tf.Int64, op.PlaceholderShape(tf.MakeShape(2, 2)))\x := op.Placeholder(root, tf.Int64, op.PlaceholderShape(tf.MakeShape(2, 1)))\\
变更之后:
\\\// define 2 subscopes of the root subscopes, called \"input\". In this\// way we expect to have a input/ and a input_1/ scope under the root scope\A := op.Placeholder(root.SubScope(\"input\"), tf.Int64, op.PlaceholderShape(tf.MakeShape(2, 2)))\x := op.Placeholder(root.SubScope(\"input\"), tf.Int64, op.PlaceholderShape(tf.MakeShape(2, 1)))\fmt.Println(A.Op.Name(), x.Op.Name())\\
照常对其进行编译及运行: go run attempt2.go。结果如下所示:
\\\input/Placeholder input_1/Placeholder\\
提问时间:
\\到现在,我们了解到关于TensorFlow架构的哪些结论? 一个节点完全由其定义所在的Scope负责标识。该范围为一条路径,我们利用其实现由图形root到目标节点的追踪。我们可以通过两种节点定义方式确保其执行同样的运算:在不同Scope当中定义该运算(Go风格)或者变更运算名称(Python会自动执行这一操作,我们亦可在C++中以手动方式执行)。
\\到这里,我们已经解决了节点命名重复的问题,但仍有另一个问题需要加以探讨。
\\\\\\\panic: failed to add operation \"MatMul\": Value for attr 'T' of int64 is not in the list of allowed values: half, float, double, int32, complex64, complex128\\\
为何MatMul节点会出现定义错误?我们只是希望将两项tf.int64指标相乘!看起来,MatMul似乎单单无法接受int64类指标。
\\\\\\\int64的attr ‘T’值并不符合允许值的定义要求: half, float, double, int32, complex64, complex128
\
这里列出的定义要求到底是什么意思?为什么我们能够将两项int32指标相乘,却无法对两项int64指标进行同样的运算?
\\下面我们将逐步解决这个问题。
\\结论三:TensorFlow类型系统
\\下面我们着眼于源代码内容,看看C++对MatMul运算作出的声明:
\\\REGISTER_OP(\"MatMul\")\ .Input(\"a: T\")\ .Input(\"b: T\")\ .Output(\"product: T\")\ .Attr(\"transpose_a: bool = false\")\ .Attr(\"transpose_b: bool = false\")\ .Attr(\"T: {half, float, double, int32, complex64, complex128}\")\ .SetShapeFn(shape_inference::MatMulShape)\ .Doc(R\"doc(\Multiply the matrix \"a\" by the matrix \"b\".\The inputs must be two-dimensional matrices and the inner dimension of\\"a\" (after being transposed if transpose_a is true) must match the\outer dimension of \"b\" (after being transposed if transposed_b is\true).\*Note*: The default kernel implementation for MatMul on GPUs uses\cublas.\transpose_a: If true, \"a\" is transposed before multiplication.\transpose_b: If true, \"b\" is transposed before multiplication.\)doc\");\\ 此行代码为MatMul运算定义了一个接口:具体来讲,我们可以利用REGISTER_OP宏对该运算作出以下描述:
\\- 名称: MatMul\\t
- 参数: a、b\\t
- 属性(可选参数): transpose_a、transpose_b\\t
- 支持的模板T类型: half, float, double, int32, complex64, complex128\\t
- 输出形式: 自动推断\\t
- 文档\
这套宏不会调用任何C++代码,但我们可以从中看到,在对一项运算进行定义时,即使使用一套模板,我们亦必须保证其中的T类型(或者属性)存在于受支持类型列表当中。实际上,.Attr(\"T: {half, float, double, int32, complex64, complex128}\")属性会将T类型约束为该列表当中的一个具体值。
\\正如教程当中所提到,即使是在使用模板T时,我们同样需要面向各受支持重载明确进行内核注册。此内核采用CUDA方式以引用以并发方式执行的各C/C++函数。
\\正因为如此,MatMul的作者决定仅支持以上列出的几种类型,并将int64排除在外。其作出这一决定的理由有二:
\\- 用于监督:有可能是这样,毕竟TensorFlow的作者仍然是人类!\\t
- 为了支持那些无法完全支持int64运算的设备——具体来讲,一部分受支持硬件可能无法充分完成这类运算过程。\
再回到问题身上来:现在解决办法已经非常明确。我们需要将受支持类型的参数传递至MatMul处。
\\这里我们创建attempt3.go以利用int32引用每一行代码中的int64。
\\这里只需要注意一点:Go绑定拥有自己的一组类型,且其与Go类型(几乎)属于1:1映射关系。当我们将各值包馈送至图形当中时,我们必须尊重这一原始映射关系(例如在定义tf.Int32占位符时馈送Int32)。在从图形中提取数值时同样遵循此理。 返回自Tensor评估的*tf.Tensor类型拥有Value()方法,而此方法则返回一个必须被转换为正确类型的interface{}(这一点已经在图形架构当中有所体现)。
\\编译并运行go run attempt3.go。结果如下:
\\\input/Placeholder input_1/Placeholder\[[210] [-210]]\\
万岁!
\\到这里,我们已经展示了完整的attempt3代码; 大家可以对其进行构建与运行(当然,如果发现了改进空间,您亦可为其作出贡献)。
\\提问时间:
\\\\到现在,我们了解到关于TensorFlow架构的哪些结论? 每一项运算都拥有自己的一组关联内核。作为一种描述性语言,TensorFlow属于强类型语言。其不仅要求用户遵守C++类型规则,同时亦要求在运算注册阶段指定特定类型方可实现功能。
\\总结
\\通过利用Go语言定义并执行图形,我们得以更好地理解TensorFlow框架的底层结构。而通过试错法,我们亦得以一步步解决各个简单问题,最终掌握与图形、节点以及类型系统相关的重要知识。
\\查看英文链接:
\\感谢对本文的审校。
\\给InfoQ中文站投稿或者参与内容翻译工作,请邮件至。也欢迎大家通过新浪微博(,),微信(微信号:)关注我们。
转载地址:http://gugjx.baihongyu.com/